Cinta de Moebio: Revista de Epistemología de Ciencias Sociales
Satriano, C. y Moscoloni, N. 2000. Importancia del análisis textual como herramienta para el análisis del discurso. Cinta moebio 9: 287-306
Importancia del análisis textual como herramienta para el análisis del discurso
The importance of textual analysis as a tool for speech analysis
Cecilia Raquel Satriano. Psicóloga por la Universidad Nacional de Rosario.
Nora Moscoloni. Estadística. Profesional principal de CONICET, con sede de trabajo en I.R.I.C.E.
Abstract
In our research we use textual analysis techniques of speech analysis, to know the abandon representations from subjects whom has interrupted they therapy. Identify this group’s speech, enable us to delimitated significant aspects of they discourse and obtain significant elements from the language.
Key words: textual analysis, speech analysis, therapy.
1. Algunas Aproximaciones a la Noción de Análisis del Discurso
1.1. Su Concepto
El análisis del discurso es un campo nuevo que implica un enfoque interdisciplinario, es decir que ha surgido desde distintas disciplinas, básicamente, humanísticas y orientadas a las ciencias sociales. Sin embargo, se encuentran antecedentes importantes en la retórica, hace más de 2000 años. Aristóteles, por ejemplo, clasificó diferentes estructuras del discurso señalando su efectividad en los procesos de persuasión en contextos públicos (Van Dijk, 1990) (1).
Sin abundar en los antecedentes acerca del origen de la lingüística desde Saussure, el desarrollo del análisis del discurso está relacionado con el surgimiento del estructuralismo y, especialmente de los formalistas de la década de los sesenta quienes tomaron conciencia de la importancia de la retórica (Lausberg, 1960) (2); (Erlich, 1965; Todorov, 1969; Barthes, 1970; Corbertt, 1971) (3). A partir de Greimas quien desarrolla la semántica, se reconstruye el contenido a partir de las dimensiones del significado elemental de la palabra (1966) (4).
Posteriormente se efectuaron análisis funcionales semejantes respecto a la oración que fueron utilizados para caracterizar significados totales del discurso (Van Dijk, 1990).
En la actualidad, el análisis del discurso incluye varias ramas como la lingüística del texto, la gramática del texto y otros enfoques del discurso, conformando una nueva pluridisciplina que estudia el texto y el habla o el uso de la lengua desde todas las perspectivas posibles.
El análisis del discurso tiene definiciones muy variadas. Una definición muy amplia es aquélla que plantea que es el análisis de la lengua en su uso puesto que investiga el para qué se utiliza la lengua (Brown & Yule, 1993).
Van Dijk, por su parte, asevera que es "el estudio del uso real del lenguaje por locutores reales en situaciones reales" (1985) (5). En algunos países anglosajones el análisis del discurso está identificado al análisis de conversaciones, puesto que consideran que el discurso es una actividad interactiva. Otras acepciones consideran que el análisis del discurso es una disciplina que en vez de proceder a un análisis lingüístico del texto, o a un análisis sociológico o psicológico de su contexto, tiene como objetivo articular su enunciación con un determinado lugar social (géneros discursivos). Por lo tanto, el análisis del discurso es un punto de encuentro en las ciencias humanas, lo que produce que sea inestable en cuanto a su definición. Algunos apuntan a lo sociológico, a lo psicológico, a lo lingüístico, a lo antropológico, a lo psicoanalítico, etc.
1.2. El Texto como Objeto
En primera instancia, situaremos al ‘texto’ como un término técnico que hace referencia al registro verbal de un acto comunicativo (Brown & Yule, 1993) (6). Caracterizar al texto como objeto hace notar la posición de Noam Chomsky, quien plantea que existen productores y receptores de oraciones, o de textos más extensos pero, cuando hablamos de análisis de un texto estamos refiriéndonos, únicamente, al producto. Es decir, a las palabras que aparecen sobre las páginas. En este sentido, el análisis no incluye ninguna consideración a la forma de cómo se produce el texto ni tampoco a cómo se recibe (1968) (7).
Por otra parte, abordar la problemática del texto es comenzar a transitar un camino que nos lleva a adentrarnos en la semiótica textual, en el examen del texto. La semiótica está enlazada con la doctrina de los signos pero, también encontramos que trata acerca de la reflexión sobre los sistemas de significación complejos y su realización en el texto. Esta posición ha producido un serio cuestionamiento del párrafo anterior (Eco, 1975) (8), (Barthes, 1980) (9).
La cuestión que se dirime tiene que ver con lo que produce el sentido. Para Benveniste, el sentido no está dado por la suma de signos sino por su funcionamiento textual (1977) (10). Cuando trabajamos con textos, sean escritos u orales, ellos son considerados como los primeros datos que sirven a un sinnúmero de disciplinas que van desde la sociología, la lingüística, la psicología social y clínica. Es decir, todas aquellas que se interesan por el estudio de la enunciación.
El texto, según la Escuela de Tartu (Bajtin, 1977) (11) (Lotman, 1979) (12) es un conjunto de signos coherentes o también cualquier comunicación registrada en un determinado sistema sígnico, donde pueden considerarse incluidos los distintos tipos de comportamientos: una pieza de teatro, una obra de arte, etc. Lo importante es la coherencia como uno de los elementos constitutivos de la definición de texto.
1.3. La Coherencia del Texto
Según Hjelmslev, la coherencia es equiparable a la consistencia y esto entraña elementos de conexión. Para Van Dijk en su libro Texto y Contexto, la coherencia es una de las propiedades semánticas de los discursos, basada en la interpretación de cada frase individual, y a su vez, relacionada con la interpretación de otras frases (1980) (13). Esto se enlaza con lo que Bellert plantea como necesario para interpretar adecuadamente una enunciación recurrente en un discurso, que requiere de los elementos que preceden a ese discurso, es decir del contexto. En este sentido este autor dice que la coherencia textual no está conferida sólo por lo que se dice en el texto sino también por lo implícito (1970) (14).
Ahora bien, para Dressler los factores que originan la coherencia son: la sustitución diafónica, la conjunción, las partículas, la estructura de modo, de tiempo y de aspecto de los predicados y, sobretodo, el orden de las palabras (1974) (15). No obstante, Van Dijk plantea que la coherencia textual se determina, solamente, en el nivel de las relaciones interfrásticas y es lo que permite la coherencia global. Este aspecto será retomado más adelante en su relación con el análisis textual.
La estructura semántica del discurso está dada por el tema o el asunto del discurso. Esta perspectiva es una importante apreciación para las áreas disciplinares de ciencias sociales puesto que el tópico textual es lo que está estrictamente conectado con la interpretación que el lector está inducido a dar al texto. Es decir, la estructura semántica remite a la coherencia global o nivel pragmático en donde, el que interpreta reconstruye el texto en dos direcciones: por un lado en la acción de recuperar información semántica que el texto posee, pero además de transferir todos los elementos propios como los supuestos socio culturales e ideológicos, los sistemas de creencias, etc.
Por otra parte, hemos de considerar el marco propio que todo texto posee y que es lo que contribuye al significado y a la coherencia textual. Según Lotman, el texto se deforma en el proceso de decodificación realizado por el destinatario (1980). Esta deformación tiene una directa relación con las críticas a la lematización en el análisis textual, la cual impone una problemática de lengua (16).
El concepto de coherencia y cohesión se ve enriquecido por el de isotopía de Greimas el cual se basa en la existencia de repetición, reiteración o redundancia de elementos similares o compatibles (1976) (17). La isotopía es una propiedad semántica del texto que permite destacar los planos homogéneos de significación y que se apoya sobre la redundancia y la reiteración en varios segmentos textuales de algunos elementos semánticos idénticos.
La isotopía es la coherencia interna, es decir que aborda el problema intratextual de la coherencia de los discursos (Greimas, 1966, 1973) (18). Cuando el concepto de coherencia intenta ser aplicado a un discurso es la isotopía lo que aparece a primera vista, "la permanencia recurrente a lo largo de un discurso de un mismo haz de categorías justificativas de una organización paradigmática" (Greimas, 1976). Por esta razón, la repetición constituye una condición necesaria para que una secuencia sea coherente (Bellert, 1970) (19). Weinrich ha expresado que este concepto es la textualización de todo el campo de palabras (1981) (20).
La isotopía es una propiedad semántica del texto que permite destacar los planos homogéneos de significación, mediante la redundancia y reiteración de varios segmentos textuales de algunos elementos semánticos idénticos.
La isotopía semántica es la que estudia las redundancias formales del contenido y la que posibilita designar a la isotopía como propiedad semántica del texto. Es decir, se puede hablar de dos isotopías, entre otras; una ligada al plano del contenido y otra relacionada con el plano de la expresión. El análisis textual, por su parte, dará elementos para el estudio de la isotopía en el plano del contenido, como veremos más adelante.
1.4. El Discurso
Debemos considerar al texto como un proceso semiótico que en su tránsito sintáctico va produciendo sentido. Paul Ricoeur planteaba que "el sentido del texto no es nada que lo refiera a una realidad exterior al lenguaje; consiste en las articulaciones internas del texto y en la subordinación jerárquica de las partes al todo; el sentido es el ligamen interno del texto" (1977) (21). Por esta razón, cuando hacemos referencia al discurso, su existencia se basa en elementos recurrentes del texto que tienen un aspecto procesual, el cual permite el funcionamiento semiótico.
Kristeva, por su parte, plantea que el texto o discurso puede ser entendido como "un aparato translingüístico y que supone un tipo de producción significante que ocupa un lugar preciso en la historia (1970)" (22).
Es el paso de la lengua a la palabra y al discurso, es decir, el desplazamiento del sistema al proceso lo que permite la definición del discurso como proceso semiótico.
Para Hendriks, el discurso no debe ser considerado sólo como perteneciente a la palabra, o como formando parte del uso de la lengua sino como posible unidad formal del sistema lingüístico (1976) (23).
El discurso puede identificarse con el enunciado o, más concretamente, con lo que es enunciado. La enunciación da cuenta del conjunto de procedimientos formales que generan y organizan el discurso. El enunciado es el resultado de la enunciación.
Desde la perspectiva de Gonzalo Abril, Jorge Lozano y Cristina Peña Marín el estudio del discurso enunciado debe realizarse conjuntamente con el estudio de la enunciación que en un sentido constituirá su contexto (1997).
Halliday considera al texto en su concepción más general diciendo que es un intercambio social de sentido en tanto es un hecho sociológico y un encuentro semiótico a través del cual los significados que constituyen el sistema social se intercambian (1976). La característica central del texto es para este autor, la de ser interacción entre sujetos, el intercambio de significados (1982) (24). En cambio, para Cicourel el discurso es intercambio de actos de habla (1980) (25). Por esta razón, este autor plantea que el discurso está siempre incluido en un contexto más amplio que, según Malinowsky podría ser el contexto cultural o de la situación (1964) (26).
Para Schmidt los textos son configuraciones lingüísticas objeto de una expectativa social que aparecen como un conjunto de conformaciones que poseen una función ilocutiva y una perlocutiva en actos de comunicación (1977).
A partir de estas definiciones es que nosotros nos preguntamos si era posible indagar los aspectos indiciales del enunciado a través del análisis textual.
1.5. Nociones y Principios del Análisis del Discurso como Técnica Metodológica
La interpretación de un texto implica recuperar la información semántica pero además, introducir los elementos que el interpretador aporta y que van desde los supuestos socioculturales e ideológicos, los sistemas de creencias, los subcódigos, etc.
El discurso, como las oraciones, puede mostrar estructuras de naturaleza sistemática, con propiedades individuales determinadas por el contexto. Al respecto, existe una diferencia entre el texto como objeto formal y el discurso. Van Dijk plantea que el principal objetivo del análisis del discurso es producir descripciones explícitas y sistemáticas, tanto textuales como contextuales, de unidades del uso del lenguaje al que se denomina discurso (1990). Las dimensiones textuales se refieren a las estructuras del discurso en diferentes niveles de descripción, mientras que las contextuales relacionan a éstas con las propiedades del contexto.
El análisis del discurso contempla, por lo menos, dos niveles lingüísticos relevantes: el sintáctico y el semántico. El primer nivel es el sintáctico estructural de los enunciados, en donde se profundiza en la caracterización formal que adquiere la estructura gramatical. El segundo nivel del análisis es el semántico en el cual se profundizan las características de las respuestas y se incluyen el sentido, en el nivel de las unidades significativas elementales y no en el nivel de los elementos (signos) (27). Estos dos niveles permiten reducir la multidimensionalidad del fenómeno discursivo observado, posibilitando de esta manera, dar un paso más en esta lógica de la reducción cualitativa. Pero también, la acción discursiva y la acción enunciativa son ámbitos que se completan con un análisis de los niveles semánticos y sintácticos del texto porque son, a su vez, complementarios.
Las descripciones textuales, sobre todo el discurso escrito, acuden a la sintaxis y a la semántica. La sintaxis describe categorías como sustantivos o frases sustantivas que aparecen en las oraciones, incluyendo las combinaciones posibles y las formas más globales del discurso. La semántica, por su parte, se encarga de los significados de las palabras, de las oraciones y hasta del discurso. La semántica asigna interpretaciones a las unidades, dentro de unidades mayores y también considera el significado y la referencia de los objetos y las cosas para describir la coherencia discursiva. Existen además, el componente pragmático de la descripción que es lo que nos permite conocer el acto social específico que forma parte del discurso.
Los tres aspectos principales o niveles del discurso son: las formas de la oración, los significados y los actos del habla. Pero, existen otros niveles descriptivos más globales que incluyen las partes del discurso o el discurso completo. Van Dijk la denomina macrosemántica porque permite describir los significados de párrafos o capítulos del texto escrito. Lo mismo sucede con la macrosintaxis y la descripción pragmática, la cual puede incluir componentes más globales.
Greimas dijo que "el discurso es el lugar de construcción de su sujeto (…) A través del discurso el sujeto construye el mundo como objeto y se construye a sí mismo (1976) (28), (1979) (29)". Por esta razón, la utilización de esta técnica permite lograr un nivel interpretativo más profundo que en los enunciados textuales, descubriendo al final del recorrido textual al sujeto de la enunciación.
El nivel pragmático es el último en el proceso del análisis puesto que es el que nos permite establecer la relación de las frases con los sujetos con quienes las usan e interpretan como modo de acción. Es de observar que el discurso, en este sentido, no está constituido por un conjunto de proposiciones solamente sino por una serie de acciones. Este nivel posibilita conocer los aspectos instrumentales del lenguaje es decir, las diversas situaciones en la que se producen los discursos y las consecuencias o efectos que éstos promueven.
2. Aproximación Estadística al Texto
El Análisis de Datos Textuales es una aplicación de los métodos de Análisis de Datos en la perspectiva de la escuela francesa, es decir, métodos de análisis multidimensionales exploratorios.
Las primeras aplicaciones fueron realizadas por Benzécri, quien desarrolló el análisis de correspondencias para discutir las tesis de Chomsky sobre la lengua (30). Posteriormente, L. Lebart, a raíz de su trabajo en el CREDOC, continuó los desarrollos ante la necesidad de tratar preguntas abiertas con métodos más automáticos que la post -codificación manual que entonces se hacía y que en la mayoría de los casos aún se sigue realizando. A su vez, se debe a M. Bécue el desarrollo de un paquete informático para el tratamiento de datos textuales, el SPAD.T (1989) (31).
La idea de tratar textos con métodos estadísticos no es nueva. El equipo de Saint-Cloud ha trabajado por años lo que han denominado estadística léxica, produciendo importantes investigaciones en el marco del análisis factorial de correspondencias, con objetivos muy similares: "encarar el problema del discurso en forma sistemática, muy representativa tanto de las posibilidades como de los límites de la utilización de los instrumentos estadísticos" (Maingueneau, 1989) (32).
En los primeros textos se aplicaban los métodos estadísticos elaborados para tratamiento de variables continuas. Sin embargo, los principales y más interesantes resultados se obtuvieron aplicando los métodos de análisis multidimensional de datos para variables nominales.
El Análisis de Datos Textuales consiste en aplicar estos métodos, en especial el análisis de correspondencias y la clasificación a tablas específicas, creadas a partir de los datos textuales. Estos métodos se completan con métodos propios del dominio textual como los glosarios de palabras, las concordancias y la selección del vocabulario más específico de cada texto, para así proveer una herramienta comparativa de los mismos.
¿A qué tipo de datos textuales se pueden aplicar esos métodos? El ámbito en el cual es más fácil aplicarlos son las preguntas abiertas de encuestas y en general a numerosos textos cortos. Si bien el campo de aplicación es bastante amplio, es deseable tener textos que presten cierto grado de homogeneidad y de exhaustividad en el tema a estudiar, esto se relaciona con el concepto de coherencia en Van Dijk (1980).
El principio fundamental en esta perspectiva es el análisis a través de la comparación. Se busca comparar entre sí el discurso de los individuos que han contestado a una encuesta o preguntas pautadas en entrevistas personales, o de grupos de individuos con características comunes. Por ejemplo: el lenguaje de los hombres con el de las mujeres, el lenguaje de los jóvenes con el de los mayores. En un ámbito literario permite asimismo comparar textos. La comparación implica llegar eventualmente a clasificar a los individuos o a los textos en clases homogéneas en cuanto al vocabulario empleado. También puede interesar clasificar palabras. Estos métodos pueden resumir los textos mediante las palabras y las respuestas o frases más características, concepto que desarrollamos más adelante (3.7.).
Un objetivo importante es conectar las repuestas abiertas con toda la información proporcionada por las respuestas cerradas o variables categóricas relativas a características contextuales de los individuos.
El conjunto de las respuestas abiertas a una pregunta de encuesta o entrevista forma lo que llamamos, siguiendo a los lingüistas el "corpus estudiado", si bien éste es un corpus particular en el sentido del tratamiento que se hace del mismo.
Los métodos estadísticos lexicométricos se proponen como sistemáticos, en el sentido de que cuentan la presencia de las palabras sin una selección a priori. Son exhaustivos, porque trabajan a partir del texto de todas las respuestas y por lo tanto, son métodos que permiten una mayor objetivación, o por lo menos posibilitan retrasar la introducción de la subjetividad hasta una fase más tardía del trabajo (33).
En nuestra investigación, el análisis textual permitió facilitar en primera instancia el análisis sintáctico a través del procedimiento de listas de palabras y profundizar en el aspecto semántico a través de la exploración de grandes dimensiones de significado. Utilizamos para ello el análisis factorial, la clasificación y la búsqueda de palabras y frases características.
2.1. Selección de las Unidades: Las Formas Gráficas
El primer problema que se plantea es la elección de la unidad estadística con la cual se va a trabajar. La que surge en forma inmediata es la palabra en el tratamiento computacional, sin embargo es necesario remitirse a las formas gráficas, es decir a las palabras tal como vienen escritas, de manera que singular y plural de un mismo sustantivo son dos formas distintas así como las distintas inflexiones de un verbo.
Esta es la unidad básica de recuento que empleamos, a posteriori se puede lematizar, es decir reagrupar las distintas inflexiones de un verbo en el infinitivo; el singular y el plural de un sustantivo en el singular; el masculino y el femenino de un adjetivo en el masculino. Esta posibilidad no se puede aplicar a todos los corpus. En nuestro trabajo ‘tratamiento’ y ‘tratamientos’ no remitían al mismo significado. Se aconseja entonces dejar la lematización para una fase ulterior. El software con el cual trabajamos permite lematizar manualmente, es decir creando listas explícitas de equivalencias (34).
3. Aplicación en una Investigación acerca de los Abandonos del Tratamiento en Pacientes Drogadependientes
Esta investigación se llevó a cabo en la ciudad de Rosario, y permitió extraer un material lo suficientemente rico como para analizar el problema de los abandonos en los pacientes drogadependientes. En este sentido, la interrupción del tratamiento constituye uno de los aspectos que más han sido descuidados por los modelos terapéuticos. Esto se debe, fundamentalmente, a la ausencia de implementación de programas de seguimiento que evalúen los procedimientos, mientras tiene lugar el tratamiento.
Específicamente, la finalidad de la indagación fue identificar a través de los elementos enunciativos obtenidos en los pacientes abandonantes, las representaciones de la interrupción y las consecuencias de la experiencia del tratamiento, evaluando los cambios subjetivos producidos en ellos.
Para la evaluación del modelo de tratamiento se elaboró una lista de veinticinco personas, quienes representaban un poco más del 50 % del total de abandonantes del programa, entre los años 94 y 95.
Las personas que compusieron la muestra fueron seleccionadas del programa A.V.C.D., cuyo abordaje está basado en el modelo de Comunidad Terapéutica (35). En la selección de la muestra no se tuvieron en cuenta las características de corte probabilístico sino intencional, de acuerdo con los el diseño general de la investigación, en la cual se trabajó con procedimientos cualitativos, exclusivamente.
El grupo de sujetos fue elegido siguiendo dos criterios:
- Que éstos hubiesen dejado el tratamiento en la fase de Reinserción.
- Que el tiempo del abandono no fuese menor de seis meses ni mayor de un año y medio.
Los dispositivos técnicos seleccionados para la recolección de los datos fueron entrevistas semi- estructuradas, confeccionadas con una guía de preguntas que permitiesen captar la representación del abandono de los sujetos entrevistados. Para esto fue necesario incluir seis tópicos, mediante los cuales pudiésemos obtener distintas representaciones acerca de la experiencia en el tratamiento, pero a la vez conocer los problemas que los llevaron a interrumpir. De esta manera obtuvimos agrupamientos textuales, ordenados según los tópicos de las entrevistas semidirigidas:
- Percepción acerca del abandono del tratamiento.
- Cambios producidos a partir de la permanencia en el programa.
- Aspectos que no se hubieran modificado a pesar del tiempo de tratamiento. Críticas al programa.
- Representación de sí mismo antes y después de la experiencia terapéutica.
- Lugar que ocupaba la droga en su vida.
- Expectativas respecto al tratamiento.
Al respecto, se obtuvo un total de 22 entrevistas, mediante las cuales se pudieron indagar además, otros aspectos que estaban relacionados directamente con la interrupción de la terapia como ser: la representación del tratamiento, consideraciones respecto de los efectos positivos y los obstáculos en el mismo, la propia representación antes y después de la experiencia, y el interés y expectativas de la terapia.
3.1. Descripción y Análisis General del Corpus
A partir de la utilización del SPAD-T pudimos obtener los elementos objetivos necesarios que aparecían en el texto de los abandonantes. La primera aproximación analítica que se obtiene del programa es lexicográfica. En la Tabla I presentamos el total de las formas gráficas utilizadas por los abandonantes.
Tabla 1. Lista de Palabras
| Número total de respuestas | 22 |
| Número total de palabras | 11554 |
| Número de palabras distintas | 2027 |
| Porcentaje de palabras distintas | 17.5% |
El corpus estuvo compuesto por 11.554 formas gráficas, de las cuales descontamos las repetidas obteniendo 2.027 formas distintas. Es decir, los sujetos que habían abandonado este tratamiento utilizan un 17,5 % (36) de aprovechamiento del lenguaje oral, por lo tanto nos está indicando en una primera aproximación, que existe pobreza de vocabulario o, dicho de otro modo, el léxico empleado es reducido (37).
El déficit en la expresividad oral, lleva a pensar que las personas que han tenido alguna práctica con drogas, no están enganchadas a la palabra, sino más bien se excluyen como sujetos de la misma.
Es posible cotejar estas observaciones, que surgen a simple vista por el recurso metodológico empleado, como una de las mayores dificultades que manifiestan los terapeutas en la clínica en drogadependencia. Autores como Vera Ocampo (1988) (38), Le Poulichet (1990) (39), Maldavsky (1992) (40) nos advierten acerca de la falta de vocabulario.
En el artículo de A. Boudreau "Toxicomanías que no son alcoholismo", aparecido en la Encyclopédie médico-chirurgicale (41), se corrobora que el vocabulario de los sujetos afectados al consumo de drogas está plagado de palabras circunscriptas en su significación a lo que se denomina vulgarmente la jerga del toxicómano. El léxico empleado es reducido, en consecuencia, por la utilización frecuente de términos, marcados de sentido por el grupo de pertenencia (42).
Por su parte, Jacques A. Miller insiste en que la toxicomanía no es una experiencia de lenguaje si no que, por el contrario, "es lo que permite un cortocircuito sin mediación, una modificación de los estados de conciencia, la percepción de sensaciones nuevas, la perturbación de las significaciones vividas del cuerpo y del mundo" (1989) (43).
3.2. Umbrales Elegidos
Teniendo en cuenta el procedimiento empleado para arribar a este primer resultado, es de aclarar que posteriormente no trabajamos con todas las formas gráficas sino, únicamente, las formas repetidas un cierto número de veces.
La primera reducción del corpus se realizó agrandando la frecuencia de las palabras a tomar en consideración, puesto que algunas, al aparecer sólo una vez (44) no son significativas para el análisis. En este caso elegimos el umbral de frecuencia igual a 3 debido al volumen del corpus, es decir conservamos las formas empleadas al menos 4 veces por los entrevistados. De esta manera comparamos a los individuos, a partir de lo que tienen en común, ya que las formas empleadas una única vez no permiten comparación alguna.
3.3. Glosarios
La construcción de un catálogo de palabras o glosario es la base para la aplicación de distintos procedimientos que vayan deconstruyendo el texto. Entonces, el primer resultado es una deconstrucción que permite poner en evidencia signos totalmente transparentes al investigador cuando recorre el texto en una lengua habitual.
La tabla obtenida nos permite analizar las frecuencias de las palabras. Si por un lado es conveniente eliminar los hapax, en el otro extremo existen las formas que se repiten con demasiada frecuencia y que en general, son los nexos y otras funciones gramaticales propias de una lengua determinada y que se repiten indistintamente todo a lo largo del corpus. Las formas que más aparecen aquí son: me, que, de, no, que tienen una frecuencia superior a 300 ocurrencias. En general estas formas son consideradas palabras herramientas, es decir, las que habitualmente se usan en la lengua, lo que significa que pueden ser descartadas. Sin embargo, en el tratamiento lexicométrico, observamos que la palabra de mayor frecuencia de aparición es el dativo o sufijo del yo, me (f. 500), el cual guarda una correspondencia con las dimensiones y la temporalidad respecto de la intersubjetividad, evidentemente no podía ser eliminado (Tabla II).
Tabla II. Selección de las Palabras
| Umbral de frecuencia | 0 |
| Total de palabras retenidas | 11554 |
| Palabras distintas retenidas | 2027 |
Formas lexicales por orden de frecuencia (ver en archivo pdf)
Procedimos desagregando los elementos del texto (entrevistas de los abandonantes), pasando del aspecto léxico a la enunciación propiamente dicha y, a partir de las unidades lingüísticas indagamos los aspectos deícticos puesto que éstos son coincidentes con los hechos enunciativos (45). Vale decir, la manera de enfocar los procedimientos de análisis fue enlazando los elementos lingüísticos, que por su relevancia en el enunciado, pudieran mostrar la presencia de los hablantes, en el discurso. Destacamos algunas que nos resultaron llamativas, según la frecuencia de aparición y que determinamos con cierto contenido semántico. Estas fueron: tratamiento, droga, alcohol, sentía, era, estaba, soy, las cuales nos permitieron abrir un segundo momento del análisis.
Procedimos determinando las dimensiones en el nivel semántico a través de la abundancia de términos–objeto, discriminando los aspectos indiciales del lenguaje mediante la separación de las categorías gramaticales mínimas de los enunciados. Agrupamos en tablas, los sustantivos, los verbos y los adjetivos, teniendo en cuenta la frecuencia de aparición (Tabla III).
Tabla III. Unidades Lingüísticas de Mayor Frecuencia de Aparición
| Sustantivos | Verbos | Adjetivos y adverbios |
| Tratamiento | Sentir | Demás |
| Drogas | Ser | Siempre |
| Alcohol | Poder | Mucho |
| Vida | Hacer | Mismo |
| Familia | Tener | Muchas |
| Tiempo | Estar | Mal |
| Padres | Saber | Mejor |
| Lugar | Querer | Otro |
| Papá | Haber | Otra |
| Problemas | Dar | Poco |
| Responsabilidad | Ver | Algunas |
| Límites | Pasar | |
| Ayuda | Empezar | |
| Programa | Seguir | |
| Trabajo | Gustar | |
| Cocaína | Hablar | |
| Mamá | Pensar | |
| Grupos | Salir |
3.4. Análisis de las Unidades Lingüísticas
De acuerdo a nuestro objetivo, primeramente debimos definir la organización sintáctica dividiendo en unidades lingüísticas relevantes, a partir de las frases de los enunciados de los abandonantes, para luego estudiar el componente semántico (Benveniste, 1971) (46).
Al analizar los sustantivos como uno de los elementos que integran las unidades lingüísticas, encontramos que la mayoría de las palabras- sustantivos son conceptos del programa terapéutico, cuya connotación es tanto positiva como negativa (valorativa o desvalorativa). En este caso, el programa terapéutico es el que determina estas palabras de influencia, pero también nos permiten comprender otra cuestión, que es el resultado de una cierta estabilidad interna del discurso de estos "abandonantes". Nos referimos a la dificultad de encontrar sustantivos que marquen un real compromiso de estos hablantes como sujetos del discurso.
Al ser los sustantivos más frecuentes, las palabras del programa, esto nos indica que existe una cierta relación de exterioridad a los sujetos, que con excepción de los conceptos de vida y padres, no hay una referencia que los particularice, pero que además muestre una implicación en el lenguaje como sujeto de la enunciación (47) (48). Es decir, estas unidades léxicas no son elementos representativos propios del vocabulario de los jóvenes.
En este sentido, el análisis nos muestra, sobre todo si lo relacionamos con la pobreza de palabras, mencionada en el análisis lexicométrico, que estos sujetos no tienen un discurso complejo sino que más bien, está determinado a partir de conceptos tomados del programa de tratamiento, lo cual delimita las condiciones de producción en donde surge. No sabemos si estas condiciones precedentes, han determinado los enunciados, es decir que son los efectos de la acción del contexto, y en tal caso han pre-estructurado el discurso, o si existen cuestiones más profundas y estructurales de la subjetividad como es la carencia simbólica, evidenciada por la pobreza de vocabulario, que se observa en la clínica con los toxicómanos.
Desde un punto de vista lingüístico, el verbo es un elemento importante a tener en cuenta en los modos de estructuración enunciativa porque, como bien lo señala Benveniste (1971) es el que determina el talante descriptivo de los sujetos. Una de las principales características del verbo es, precisamente, la temporalidad, la cual se convierte en una de las categorías de análisis del discurso, fundamentales en la experiencia subjetiva. En este sentido, los verbos junto con los adverbios y las locuciones adverbiales (49) son unidades deícticas que posibilitan conocer las diferentes representaciones de los sujetos. Estas unidades léxicas o también llamadas subjetivas son textualmente identificables en relación con los tiempos verbales, deíctico, etc. porque nos permiten explicitar una evaluación del enunciador. Podemos observar que es sólo el verbo lo que permite expresar el tiempo y es a través del modo de utilización en la lengua lo que ofrece la construcción de lo real. Pero también, porque el correlato psíquico del tiempo posibilita ubicar a los sujetos de acuerdo con sus emociones y en referencia a su vida, según si el énfasis se coloca más en el pasado, en el presente o en el futuro.
Respecto de los adjetivos y adverbios, vemos que estos pertenecen a la clasificación de subjetivos. Esto significa, desde un punto de vista lingüístico, que existen dos tipos de categorías al respecto: afectivos y evaluativos. Kerbrat- Orecchione nos proporciona un concepto más definido al respecto, diciendo que: "el adjetivo evaluativo es relativo a la idea que el hablante se hace de la norma de evaluación para una categoría dada de objetos" (1997, 112-113).
Cuando analizamos el contexto relacional en donde se presentan los adjetivos y adverbios encontramos que las adjudicaciones negativas se circunscriben más a los aspectos familiares o propios de cada uno, mientras que se indica con un valor positivo tanto al programa terapéutico, como a los cambios producidos a partir de la experiencia en la institución.
En la Tabla III observamos los verbos lematizados. Como esos términos en infinitivo no reflejaban la utilización real de los tiempos volvimos a reubicarlos en otra tabla que nos mostrara los verbos según la frecuencia de aparición y respetando su conjugación (Tabla IV).
Tabla IV. Comparación entre los Verbos Conjugados de Mayor y Menor Frecuencia de Aparición
En el tratamiento analítico se destacan, primordialmente, la utilización del modo verbal pasado, y son poco frecuentes las conjugaciones en el presente (sé, tengo, puedo, soy, hay, creo, estoy, quiero, siento). El análisis nos señala la relevancia del tiempo verbal en que se expresan los enunciados de estos sujetos, porque la temporalidad es una categoría que singulariza la palabra y define su función en el discurso. En la Tabla IV vemos como aparecen ciertos dominios semánticos privilegiados conjugados en tiempo pasado que se cruzan además, con la frecuencia de uso de estas categorías (sentía, era, estaba, etc.), en los cuales se producen ciertos puntos de intersección que generan, semánticamente, una definición más importante de la temporalidad en que se representan estos sujetos.
Si la temporalidad lingüística de estos individuos está en el pasado (simple) significa por lo tanto, que los sujetos no viven su presente. Esto nos llevó a pensar que los acontecimientos pasados cargan la representación de sí, ubicándolos no en un discurso, sino en su propia historia, constituyéndose en sujetos de su historia, la cual los remite a los tiempos de drogas, consumo y dependencia (50).
3.5. Segmentos Repetidos
En los resultados anteriores falta, sin embargo, el contexto en el cual se emplean esas palabras.
Un complemento de las tablas de unidades lingüísticas fue construir un glosario de los segmentos repetidos, es decir, las sucesiones idénticas de palabras repetidas en el corpus. De la lista completa que sistemáticamente presenta el programa, extrajimos los que nos resultaron más significativos. De esta manera se ve mejor el contexto de las palabras, el sentido que pueden tener en este corpus y las temáticas más repetidas en relación con el abandono: "el tratamiento", "mi familia", "las pautas", etc.:
Tabla V. Segmentos Repetidos por Orden de Frecuencia
| Frecuencia | Segmento |
| 43 | 120-el tratamiento |
| 42 | 297-me sentía |
| 17 | 320-mi familia |
| 16 | 328-mi vida |
| 16 | 573-yo me |
| 15 | 356-no poder |
| 14 | 337-mis padres |
| 14 | 230-las pautas |
| 13 | 357-no podía |
| 12 | 300-me sirvió |
| 12 | 359-no puedo |
| 12 | 265-me cuesta |
| 11 | 339-mis viejos |
| 11 | 136-en el tratamiento |
| 10 | 189-hablar de |
| 10 | 260-los otros |
| 10 | 65-darme cuenta |
| 9 | 116-el programa |
| 9 | 273-me gustaba |
| 9 | 322-mi lugar |
| 9 | 118-el tiempo |
| 9 | 197-hacerme cargo |
| 9 | 358-no pude |
3.6. Las Concordancias y el Contexto
Otra herramienta muy útil para entender mejor el sentido de las palabras son las concordancias (51). En los estudios estadísticos, este procedimiento es considerado secundario en tanto que no aporta ningún elemento numérico a la comparación de textos. Sin embargo, su empleo es relevante para la relectura del corpus puesto que destaca de forma más pronunciada algunas frases significativas. La forma ‘ tratamiento’ es empleada 120 veces en nuestro caso pero, esto no indica el sentido en que puede ser interpretada la palabra. La concordancia es un procedimiento que nos permite obtener todos los contextos de la misma en el corpus, posibilitando acercarnos al sentido empleado, ya sea una connotación positiva o negativa (valorativa o desvalorativa). Presentamos algunas de las concordancias más significativas y teniendo en cuenta las palabras de mayor frecuencia de aparición:
- me sentía sólo en el tratamiento.
- yo no quería seguir con el tratamiento porque no respetaba las normas.
- me deprimía un poco en el tratamiento.
- pude sentir cosas muy lindas en el tratamiento.
- me sentía bien en el tratamiento.
- nunca pensé en abandonar el tratamiento.
- el sólo hecho de hablar de drogas me dan ganas de tomar alcohol.
- vivir sensaciones nuevas con mi familia sin drogas, sin alcohol.
- recurría a las drogas para tapar el dolor que me provocaba sentir angustia.
- nunca tuve responsabilidad.
- pensarme con responsabilidad me era muy extraño.
- tenía responsabilidad y era capaz de seguir adelante
- me sentía impotente
- me sentía confundido
- era un marginal
- era un impulsivo
- ya no soy el mismo
- tratar de saber quién soy
3.7. El Análisis Semántico
Profundizamos el análisis considerando la primera pregunta acerca de las causas del abandono con el fin de encontrar categorías semánticas. A partir de la tabla de frecuencias construida mediante el cruce de individuos- textos con las palabras más repetidas ya seleccionadas a partir de un umbral, se aplicó un Análisis Factorial de Correspondencias. Esta técnica permite relacionar las formas más mencionadas por los distintos individuos, es decir constituir perfiles léxicos que servirán de base para la construcción de tipologías.
Como sugiere todo enfoque tipológico, no resultan de tanto interés los perfiles aislados, serán las diferencias entre perfiles las que llamarán la atención. Aplicando la técnica de clasificación jerárquica sobre las coordenadas factoriales obtenidas mediante el análisis de correspondencias, llegamos a la formación de cuatro grupos de individuos con perfiles léxicos semejantes que referenciaron los ejes semánticos más importantes.
De esta forma creamos una nueva variable con 4 modalidades cuya distribución es la siguiente:
Tabla VI. Variable del Abandono
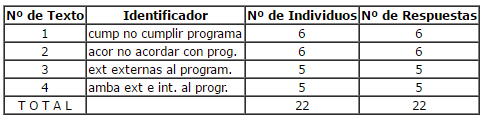
A partir de esta variable se pudo clasificar el corpus en 4 grupos obteniéndose las respuestas más características que aparecen en el texto y que son las respuestas reales de cada uno de los individuos que participaron (52). Podemos decir que se considera una forma característica de un texto cuando la misma viene sobreampliada en este texto de modo significativo teniendo en cuenta el modelo hipergeométrico que supone una selección al azar de las palabras.
Se extraen las palabras al azar siendo la hipótesis nula que cada categoría emplea más o menos la misma palabra con la misma frecuencia. La hipótesis alternativa es que hay una selección según las características del individuo y por lo tanto la frecuencia con la cual se observa la palabra en un grupo y en la totalidad de la muestra son significativamente distintas. De esta comparación surgen los valores test que se utilizan no para rechazar las hipótesis nula sino para ordenar las palabras según su grado de significación.
La interpretación de las palabras más características puede no tener mayor peso semántico, sin embargo de ellas se derivan las respuestas más relevantes relacionadas con los ejes de significación previamente determinados.
Tabla VII: Selección de individuos y respuestas características (Criterio de frecuencias de palabras)
La lectura de las respuestas características permite referenciar y dar fuerza interpretativa a los ejes semánticos construidos.
El primer eje puso de manifiesto impedimentos propios pero enmarcados en los límites que proponía ese modelo de tratamiento, problemática que debió haber sido detectada por los terapeutas en los momentos anteriores. En la fase de reinserción es cuando se flexibilizan las normas del programa, precisamente, porque es el último tramo del tratamiento. Sin embargo, encontramos que estos sujetos no tenían esas pautas incorporadas que son las herramientas esenciales del abordaje terapéutico.
En el segundo grupo aparecen fuertes críticas al funcionamiento de la institución y a las formas de intervención que fueron los determinantes del abandono. En cambio, en el tercer grupo aparecen las objeciones al programa pero enmarcadas en problemáticas personales, que llevan a una valoración positiva de la experiencia del tratamiento acumulada hasta ese momento. En este caso, la mayoría abandona por cuestiones de trabajo, lo cual está demostrando una actitud de responsabilidad que es una de las metas que pretende el modelo de comunidad terapéutica.
En el cuarto grupo aparecen combinados aspectos personales como la familia, o aspectos económicos, como también actitudes de negación de la propia historia personal, así como desaveniencias con la institución o la modalidad de abordaje. Fue este grupo el que mostró los aspectos descuidados por los terapeutas que, por otro lado, era una de las hipótesis que se planteaba en esta investigación.
A partir de conocer los cuatro criterios del abandono pudimos identificar ciertas propiedades específicas de los enunciados. Este material sirvió para indagar en las estructuras de superficie de la enunciación, hasta encontrar algunas de las categorías y reglas de formación de la estructura discursiva de estos sujetos. Además, este procedimiento nos facilitó objetivar los aspectos subjetivos de las representaciones del abandono al iniciar el análisis desde las palabras hasta las frases que componen esos enunciados.
4. Discusión
En el trabajo específico con el equipo terapéutico, se detectaron los obstáculos que habían tenido los sujetos abandonantes se logró hacer algunos cambios a nivel de las intervenciones clínicas y reforzar la preparación de algunos integrantes del equipo. La posibilidad de seguir una rigurosa sistematización de los procedimientos utilizados en el análisis textual y en el análisis del discurso determinó que encontráramos aspectos que pasaron desapercibidos como, por ejemplo las consecuencias de una de las normas básicas del programa: la prohibición de hablar de las drogas y el alcohol, durante el tiempo del tratamiento. Apoyados por el análisis semántico y pragmático que llevamos a cabo, pudimos advertir que esta restricción era inadecuada según lo demostraron los numerosos episodios de recaídas durante el último momento del programa.
El otro aspecto que detectamos fue que el programa terapéutico era visualizado por los jóvenes como un lugar ideal, sobre todo por su estructura de funcionamiento que se caracteriza por su tendencia a regular los espacios del "adentro" y del "afuera". Podría ser que la forma de estructuración del modelo terapéutico, delimitado artificialmente, fuera lo que produjera los obstáculos que se observan en la fase de reinserción.
En el análisis semántico de los propios sujetos abandonantes, obtuvimos que el tipo de discurso que se evidencia está netamente definido por la práctica con drogas, porque los enunciados que manifiestan los sujetos tienen rasgos característicos vinculados a la experiencia, anterior al tratamiento. En este caso, existe una relación de identidad que co-referencia a los participantes mediante los términos que aparecen, los cuales son de gran importancia a nivel de significante. Los hechos conectados nos evidencian que las prácticas con drogas han dejado una impronta en la delimitación temporal, en donde todo es referido a un "antes" y un "después" de la experiencia toxicómana.
La apuesta terapéutica sería instaurar un lugar que permita romper con esta mítica del pasado con drogas, sobre todo, un tiempo de composición que intente ligar las identificaciones entre las huellas, pero poniendo a distancia el camino de la alienación en las imágenes. Estas coagulaciones sobre las imágenes, son parcialmente sostenidas por las intervenciones del modelo al "prohibir" hablar de las envolturas de la droga, y no permiten que los sujetos puedan desanudarse del significante en donde se representaron como drogadictos.
Notas
- Van Dijk, T. La noticia como discurso. Comprensión, estructura y producción de la información. Paidós comunicación. Buenos Aires, 1990.
- Lausberg, H. (1960). Handbuch der literarischen rhetorik, Mgunich, Hueber.
- Referencia en La noticia como discurso. Van Dijk (1990). Ob.cit.
- Greimas, A. (1966). Semántica estructural. Larousse, París.
- Dijk, T.A Van (1985). Handbook of Discourse Analysis, 4 volúmenes, Academic Press. London.
- Brown, G. & Yule, G. (1993) El análisis del discurso. Visor Libros. España.
- Chomsky, N. (1968) El lenguaje y el entendimiento. Seix Barral, Barcelona.
- Eco, U. (1975). Tratado de Semiótica General. Editorial Bompiani, Milán.
- Barthes, E. (1980) Teoría del Texto. Enciclopedia Universalis. París.
- Benveniste, E. (1977) Problemas de Lingüística General II. Siglo XXI. México.
- Bajtin, M. (1977). El problema del texto, en A. Ponzio. Michail Bachtin. Semiótica, teoria della letteratura e marxismo, Dedalo. Bari.
- Lotman, L. y Escuela de Tartu. (1979). Semiótica de la cultura. Cátedra, Madrid.
- Van Dijk, T. (1980). Texto y Contexto. Cátedra, Madrid.
- Bellert, I. (1970). On a condition of the Coherence of Texts. Semiótica, 2.
- Dressler, W. (1974). Introduzione alla lingüística del testo, Officina. Roma.
- Según Maingueneau, la lematización es aquel procedimiento que agrupa los ítems formales o palabras gráficas sobre una base lexicográfica (poner los verbos en infinitivos, los plurales en singular). En Introducción a los métodos de análisis del discurso. Editorial Hachette. Buenos Aires, 1989).
- Greimas, A. (1976). Maupassant, La sémiotique du texte: exercices pratiques. Seuil, Paris.
- Greimas, A. (1966). Sémantique structurale. Larousse. París (traducción española, Semántica estructural, Gredos, Madrid. 1973).
- Bellert, I. (1970) On a condition of the Coherence of Texts, Semiótica 2.
- Weinrich, H. (1980). Lenguaje en textos, Gredos, Madrid.
- Ricoeur, P. (1977). La semántica de la acción. C.N.R.S. París.
- Referencia en Análisis del discurso, de Abril, G.; Lozano, J y colab. Cátedra (1997). Madrid.
- Referencia en el libro: Análisis del discurso, de Abril, G.; Lozano, J. Y col. (Ob.cit.).
- Halliday, M.A.K. (1982). El lenguaje como semiótica social. F.C.E. México.
- Cicourel, A. (1980). Language and Social Interaction: Philosofical and Empirical Issues. Working Papers-Universitá di Urbino.
- Malinowsky, B. (1964). "El problema del significado en las lenguas primitivas", en Ogden y Richards, El significado del significado. Paidós, Buenos Aires.
- Courtes, J. (1976). Introducción a la semiótica narrativa y discursiva. Editorial Hachette, Argentina.
- Greimas, A. J. (1976). La dimensión cognitiva de la narrativa discursiva. Mimeo.
- Greimas, A. J. y Courtés, J. (1979). Semiótica. Hachette. París.
- Curso de lingüística matemática de Bénzecri, J.P. en la Faculté des Sciences de Rennes (1964) y la tesis de B. Escofier- Cordier (1965) sobre el análisis de correspondencias.
- Bécue, M. (1989). Un sistema informático para el análisis de datos textuales. Tesis. Facultat d’ Informatica, Universidad Politécnica de Catalunya, Barcelona.
- Maingueneau, D. (1989). Introducción a los métodos de análisis del discurso. Hachette. Buenos Aires.
- En referencia a la lexicometría ésta es una disciplina auxiliar del análisis del discurso que tiene como objetivo la caracterización de "una formación discursiva en relación con otras que pertenezcan al mismo campo discursivo, gracias a la elaboración informática de redes cuantificadas de relaciones significativas entre sus unidades. Es un trabajo esencialmente comparativo. El resultado del cálculo está destinado a una interpretación en términos de posicionamientos ideológicos de los locutores de los enunciados" Maingueneau, D. (1999). Términos claves del análisis del discurso. Nueva Visión, Buenos Aires.
- SPAD.T. Système Portable pour l’Analyses des Données Textuelles. Lebart, L., Morineau, A., Bécue, M., Haeusler, L. (1992).CISIA. París.
- Asociación de Voluntarios para el Cambio del Drogadependiente (A.V.C.D.), cita en la calle Entre Ríos 1300, Rosario, con la cual se estableció un acuerdo marco para formalizar la investigación.
- Este resultado fue comparado con otros trabajos encontrando que, habitualmente, se usan palabras distintas en un 22 %. Trabajo de análisis del discurso de docentes publicado en el libro "Aprender a aprender". Giacobbe, M., Moscoloni,N. U.N.R., 1999.
- El problema del aprovechamiento del lenguaje oral y su tratamiento estadístico es un tema importante para profundizar en un estudio lexicométrico posterior.
- Vera Ocampo, E. (1988). Droga, Psicoanálisis y Toxicomanía, Paidós, Argentina.
- Le Poulichet, S. (1990). Toxicomanías y Psicoanálisis, Amorrortu Editores, Argentina.
- Maldavsky, D. (1992). Teoría y clínica de los procesos tóxicos, Amorrortu Editores, Argentina.
- Vera Ocampo, E. (1988). Drogas, Psicoanálisis y Toxicomanía, pp 59-60, Paidós, Argentina.
- Nos referimos a lo que se denomina como "universo del discurso" el cual abarca los datos situacionales, es decir, la naturaleza de la transmisión y la organización del espacio comunicacional, que se representan en los sujetos, a partir de la competencia cultural; y de las restricciones temático-retóricas que pesan sobre el mensaje que se va a producir en el discurso de estos grupos.
- Miller, J. (1989). Para una investigación sobre el goce erótico. Jornadas del GRETA, en el libro Sujeto, Goce y Modernidad. Fundamentos de la clínica (1995). Atuel. Buenos Aires.
- Las formas que se presentan una única vez se denominan ‘hapax’.
- Los deícticos o shifters son "clase de palabras cuyo sentido varía con la situación, los deícticos exigen, en efecto, para dar cuenta de la especificidad de su funcionamiento semántico-referencial , que se tomen en consideración algunos de los parámetros constitutivos de la situación de enunciación". Kerbrat-Orecchioni (1997). La enunciación. De la subjetividad en el lenguaje. Edicial. Argentina.
- Benveniste, E. (1971). "Los niveles del análisis lingüístico", Problemas de la Lingüística, Edit XXI, España.
- El sujeto de la enunciación es el sujeto del significante, el cual significa desde el punto de vista psicoanalítico que el sujeto queda comprometido a partir de la propia enunciación. En cambio, el sujeto del significado es la primera persona que hace uso de la palabra. (Vallejo, A. 1980). Vocabulario lacaniano. Helguero editores. Argentina.
- Desde el punto de vista lingüístico, el concepto de enunciación remite a algunas consideraciones semánticas que son necesarias dejar en claro. Según Benveniste (1970), " la enunciación es esa puesta en funcionamiento de la lengua por un acto individual de utilización"[L’appareil formel de l’énonciation, Langages]. Para Ducrot, "la enunciación es la actividad lingüística ejercida por el que habla en el momento en que habla (…) es un acontecimiento y, como tal, jamás se repiten dos veces en forma idéntica "[Anscombe, J.C.& Ducrot, O. (1976) l’argumentation dans la langue, Langages 42, junio.
- En este trabajo dejamos de lado el análisis de los adverbios y de las locuciones adverbiales del texto, no obstante la aparición de algunos términos es significativa para el análisis que se hace en el estudio. Por ejemplo, los adverbios referenciales más importantes por su aparición en el discurso de los sujetos son: acá (f; 43), ahora (22), después (18). Los dos primeros, son fundamentalmente deícticos y pueden funcionar como elementos contextuales o locaciones temporales, en el análisis.
- Benveniste diferencia historia con discurso. El discurso cubre todos los géneros en que alguien se dirige a alguien, se organiza como hablante y organiza lo que dice en la categoría de la persona. En tal sentido el discurso se inscribe en todos los tiempos verbales, mientras que la historia implica el pasado simple, y otros tiempos del pasado solamente. Problemas de Lingüística general, 1971.
- En referencia al conjunto de los contextos de una cierta forma denominada forma-polo , permitiendo localizar cada una de las ocurrencias en el corpus. Bécue Bertaut, M. (1991) Análisis de datos textuales. Métodos estadísticos y algoritmos. CISIA, Francia.
- Según Bécue " la respuesta más característica de un texto es la más próxima al perfil medio del texto que se obtiene haciendo la media de los perfiles de las respuestas del mismo"(Ob.cit.) .
Bibliografía
Benveniste, E. (1971) Los niveles del análisis lingüístico, Problemas de la Lingüística, Edit XXI. España.
Bécue Bertaut, M. (1991) Análisis de Datos Textuales, Cisia. París.
Cancrini, L., Malagoli- Togliatti, y M., Meucci,G. (1975). Droga, chi, come, perché ma soprattutto: che fare?, Sansoni. Firenze.
Cicourel, A. (1982) El método y la medida en Sociología, Editorial Nacional, Madrid.
Iñiguez y Antaki, C. (1994) El análisis del discurso en Psicología Social. Boletín de Psicología número 4. Buenos Aires.
Giacobbe M. y Moscoloni N. (1997) Aprender a aprender. UNR Editora. Rosario. Argentina
Lebart L., Morineau A., y Bécue M. (1989) - SPAD.T, Système Portable pour l'Analyse des Données Textuelles. Manuel de l'utilisateur. CISIA. París.
Lebart, L., y Salem, A. (1994) Statistique Textuelle. Dunod. París.
Maingueneau, D. (1989) Introducción a los métodos de Análisis del Discurso, Edit. Hachette. Argentina.
Maldavsky, D. (1992) Teoría y clínica de los procesos tóxicos, Amorrortu editores. Argentina.
Moscoloni, N. (1994) Análisis textual de las opiniones de estudiantes de la Universidad Nacional de Rosario. Actas de la 3era Conferencia Internacional en Análisis de Datos Textuales, Roma. Italia.
Moscoloni, N., Pallavicini, M. Valdettaro, S. y ot. (1999) Comunicación: evaluación institucional y curriculum. U.N.R. Editora. Rosario.
Navarro, P. y Díaz, C. (1994) "Técnicas y prácticas de investigación", en: Métodos y técnicas cualitativas en investigación en Ciencias Sociales, Editorial Síntesis. Madrid.
Satriano, C. (1998) La Drogadicción como objeto de discursos. Editorial Fundación Ross. Rosario.
Satriano, C., y Moscoloni N. (1998) Evaluación de los alcances terapéuticos en los tratamientos en drogadependencia, Revista de la Facultad de Psicología de la UNR, Año 1, Nº1, p. 169-176. Rosario
Satriano, C. (1995) Relevamientos institucionales, Informe 94 para el C.I.U.N.R. Publicación interna, Facultad de Psicología, U.N.R.
Satriano, C. (1996) Dificultades en la clínica en drogadependencia. Asociación Científica Argentina de Ayuda al Drogadependiente, Rosario. Argentina.
Actes de "Jornades Internacionals d'Anàlisi de Dades Textuals" JADT90. Barcelona 1990. Servei de publicacions de la UPC. Bécue, Lebart, Rajadell ed.
Actes des "Secondes Journées Internationales d'Analyse Statistique de Données Textuelles" JADT93. Montpellier 1993. Telecom, París S.J. Anastex ed.
Revista de Epistemología de Ciencias Sociales
ISSN 0717-554X